Randomized Data Splitting Leads to Inflated Performance for Seizure Forecasting Algorithms
Rationale #
Seizure forecasting algorithms could play a vital role in managing epilepsy by providing timely warnings and enabling proactive interventions; however, algorithms have historically struggled when translated to unseen, real-time data. 1 Traditionally, machine learning (ML) algorithms assume data points are independent, naively dividing into training, validation, and testing sets randomly across time. We explore different data splitting strategies and show the most common randomized strategy leads to inflated performance reporting. Thus, a more representative data split leads to significantly lower accuracies.
Methods #
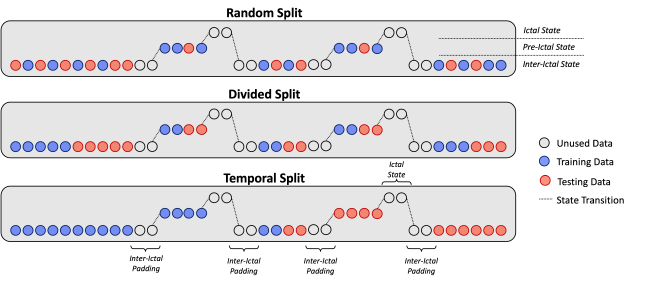
We use the publicly available CHB-MIT EEG dataset 2 and extract 5-sec segments from either 4 hours before/after the start/end of a seizure (baseline) or within 1 hour of seizure onset (preictal), under sampling the majority class to balance the dataset. Segments are organized to construct the training, validation, and testing sets using one of three time-aware methods: Random Split (RS), Divided Split (DS), or Temporal Split (TS) (Fig 1). We compare these by evaluating the performance of ML models from literature, including: a Convolutional Neural Network (CNN); a CNN plus a Long Short-Term Memory Network (CNN-LSTM) 3; and a Time Scale Network (TiSc Net) 4. Due to the patient specific nature of epilepsy, we train a new network for each patient using 10-fold cross validation on 70% of the data for parameter tuning and holding 30% of the data to for final performance metrics.
Results #
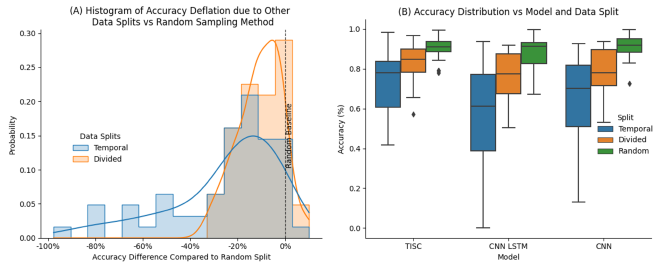
RS outperforms DS and TS, leading to over-optimistic accuracies. As shown in Fig 2, we achieve 90.9%, 88.5%, and 90.2% accuracy for CNN, CNN-LSTM, and TiSc Net respectively with RS. In comparison, DS leads to an average accuracy deflation of 11.7% and 12.4%, and TS leads to an even greater deflation of 27% and 32.5% for CNN and CNN-LSTM models respectively. TiSc Net only suffers a 7.3% and 15.9% loss in accuracy, implying this architecture may be more robust.
Conclusions #
DS and TS consistently yield lower accuracies when compared to RS, which may explain the disparity between the glowing results of offline algorithms and poor performance seen in real-time. Use of DS or TS could help researchers identify algorithms which translate to unseen data and increase efficacy in real-world applications.
Acknowledgements #
This is part of an exploration into temporal forecasting algorithms. More information can be found here.